读取excel
python
import pandas as pd
# 文件路径
file_path = "./data.xlsx"
# sheet_name 工作表名 根据具体情况传递,可以为空
# header 从第几行读取,默认为 0
sheet = pd.read_excel(file_path, sheet_name="单词管理", header=1)
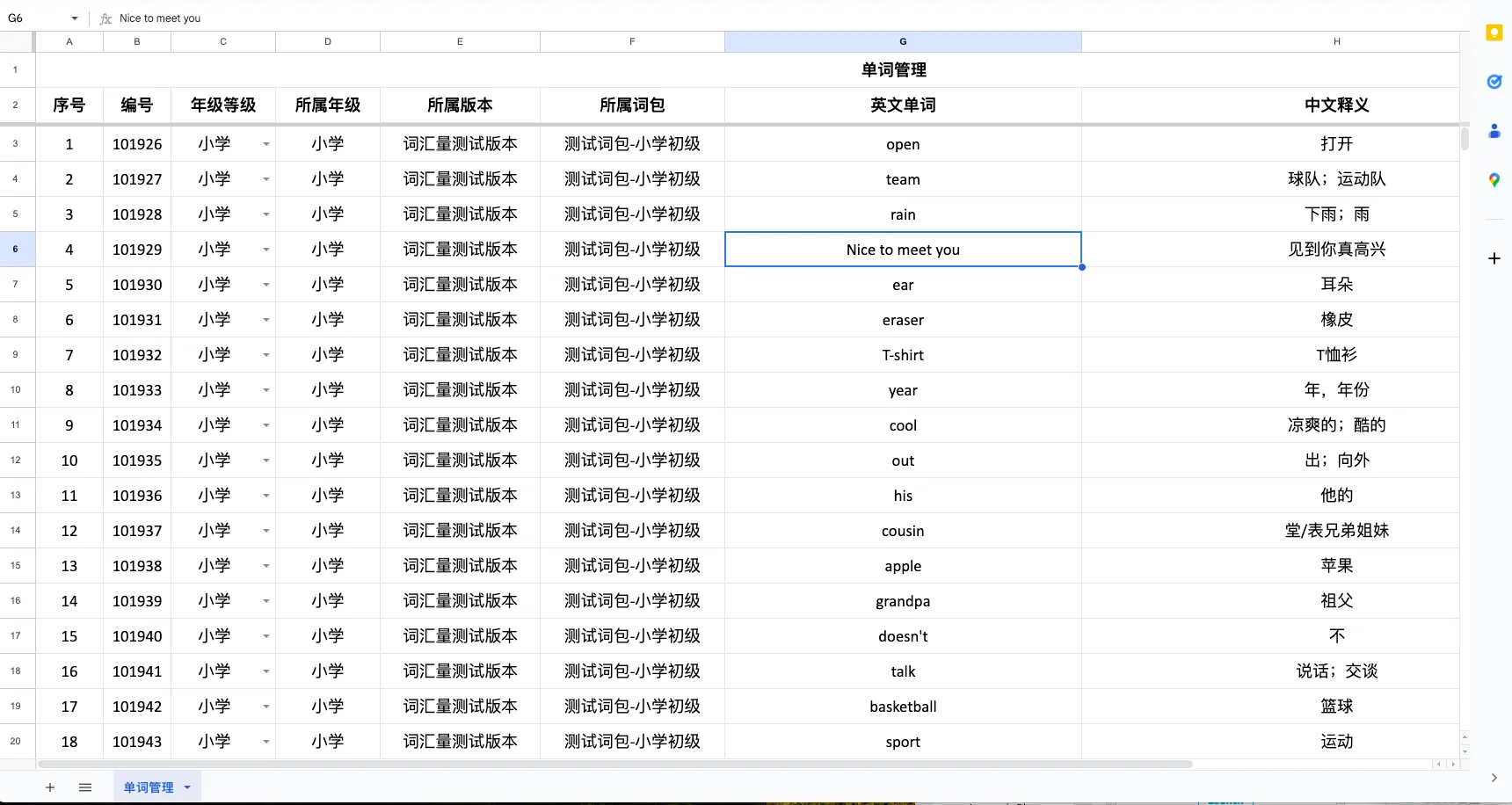
例如下面这张excel表,sheet_name就是单词管理,header就是第二行也就是应该传递1
获取列索引和行索引
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
# 获取列索引
columns = sheet.columns
# 获取行索引
index = sheet.index


选择数据
选择单列数据
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
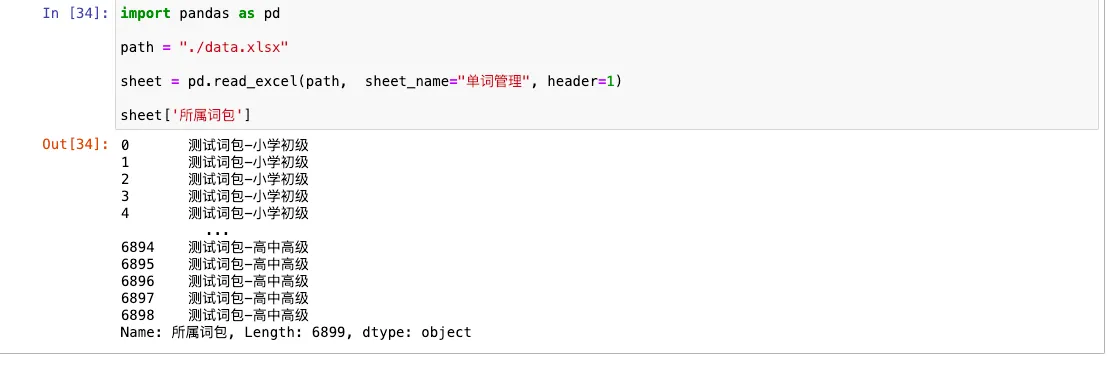
sheet['所属词包']
选择多列数据
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
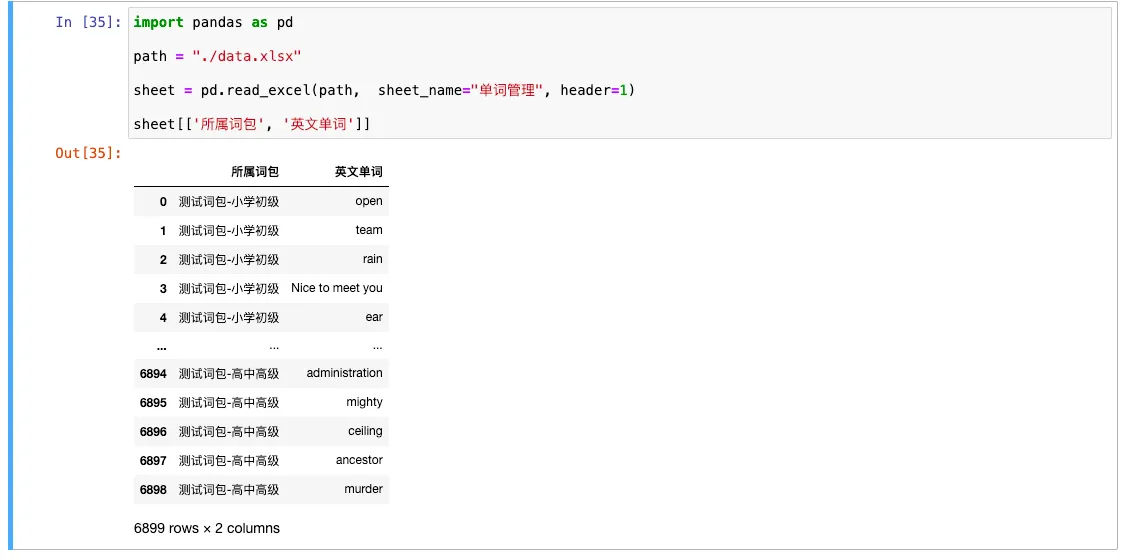
sheet[['所属词包', '英文单词']]
选择连续列或连续行的数据
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
# sheet.iloc[0:10,0:5] # 读取0到10行,0到5列的数据
# iloc 接受参数 [行切片,列切片]
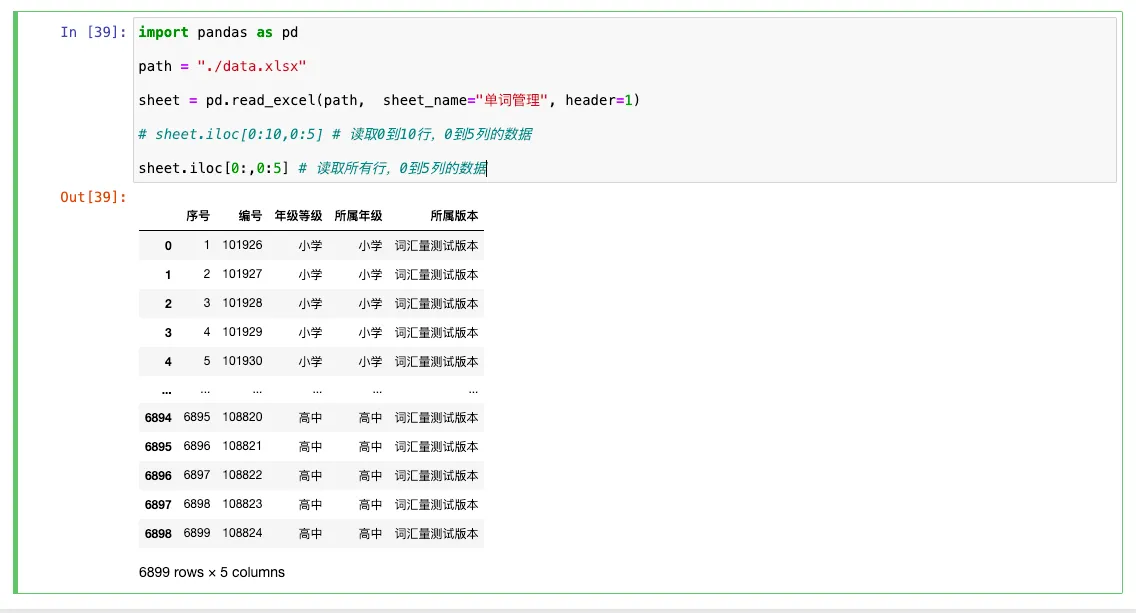
sheet.iloc[0:,0:5] # 读取所有行,0到5列的数据
选择行数据
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
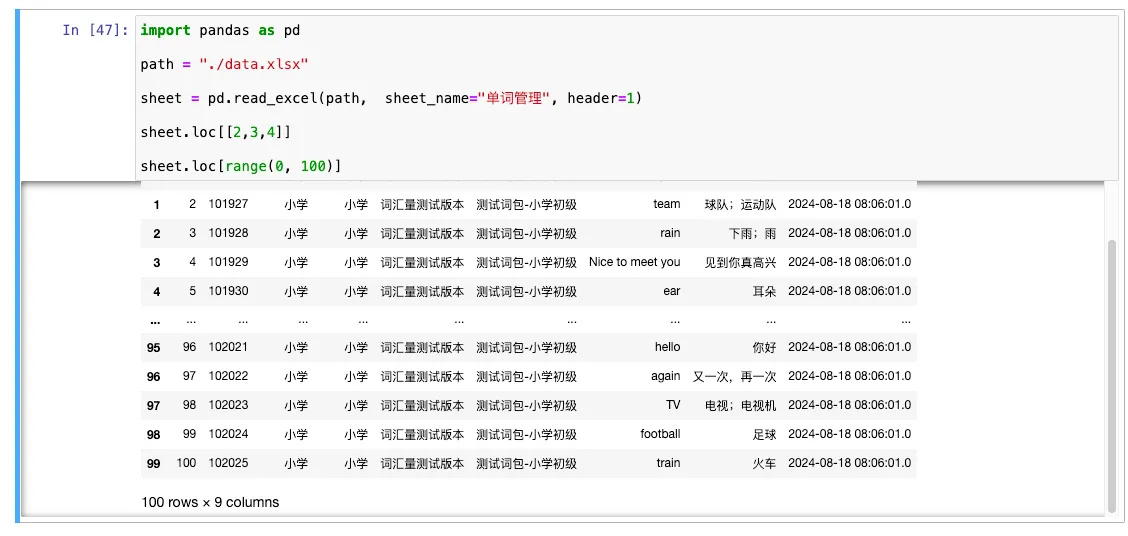
sheet.loc[[1]] # 选择单行数据
sheet.loc[[2,3,4]] # 选择多行数据
sheet.loc[range(0, 100)] # 传入一个切片选择数据
数据运算和排序
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
sheet['拼接数据'] = sheet['英文单词'] + sheet['中文释义']

python
import pandas as pd
path = "./data.xlsx"
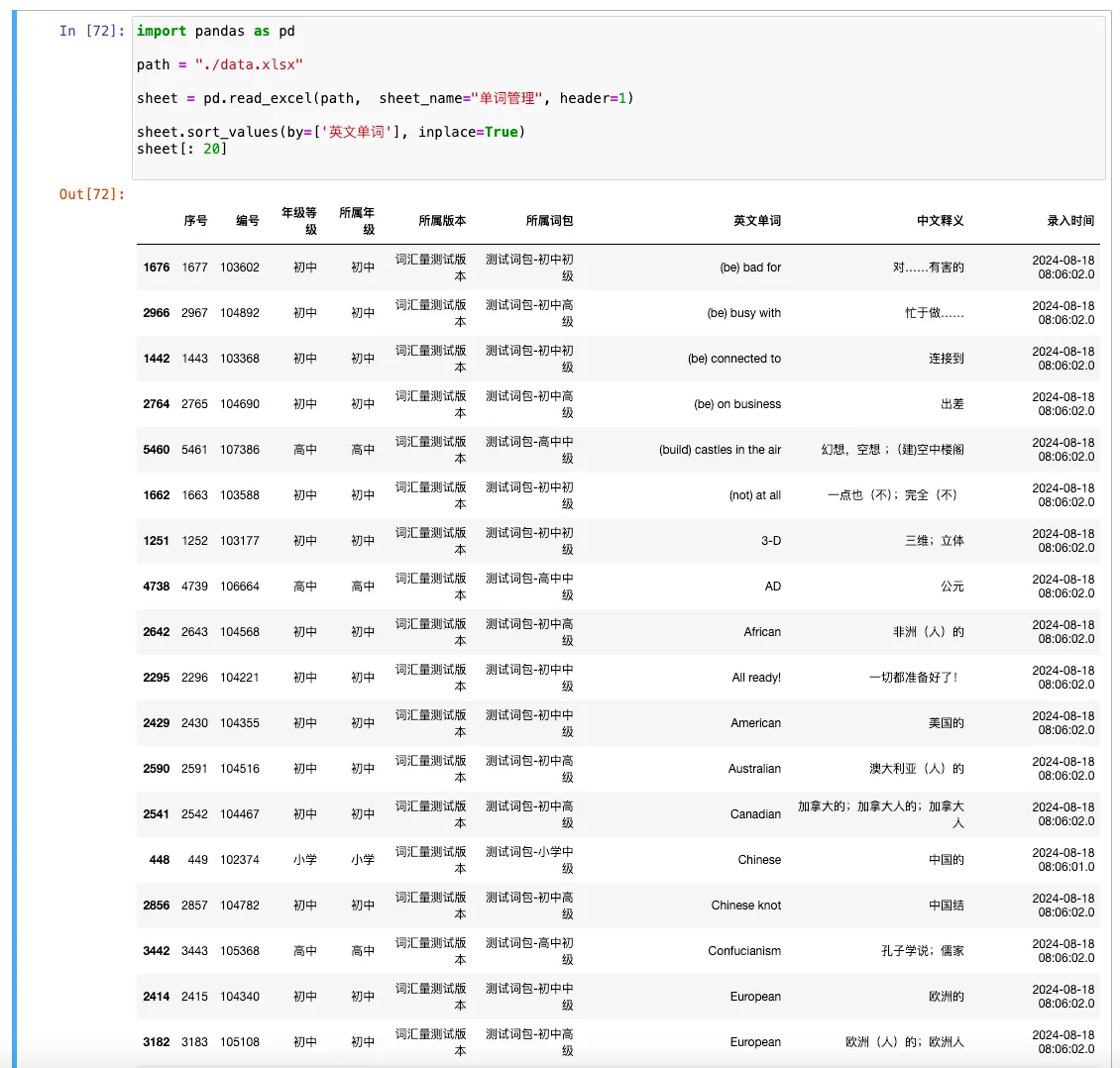
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
sheet.sort_values(by=['英文单词'], inplace=True) # 默认从小到大排序,inplace=True 表示直接修改原数据
sheet[: 20]
筛选数据
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
xiaoxue_sheet = sheet[sheet['所属年级'] == '小学']
chuzhong_sheet = sheet[sheet['所属年级'] == '初中']
gaozhong_sheet = sheet[sheet['所属年级'] == '高中']
导出到xlsx
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
xiaoxue_sheet = sheet[sheet['所属年级'] == '小学']
chuzhong_sheet = sheet[sheet['所属年级'] == '初中']
gaozhong_sheet = sheet[sheet['所属年级'] == '高中']
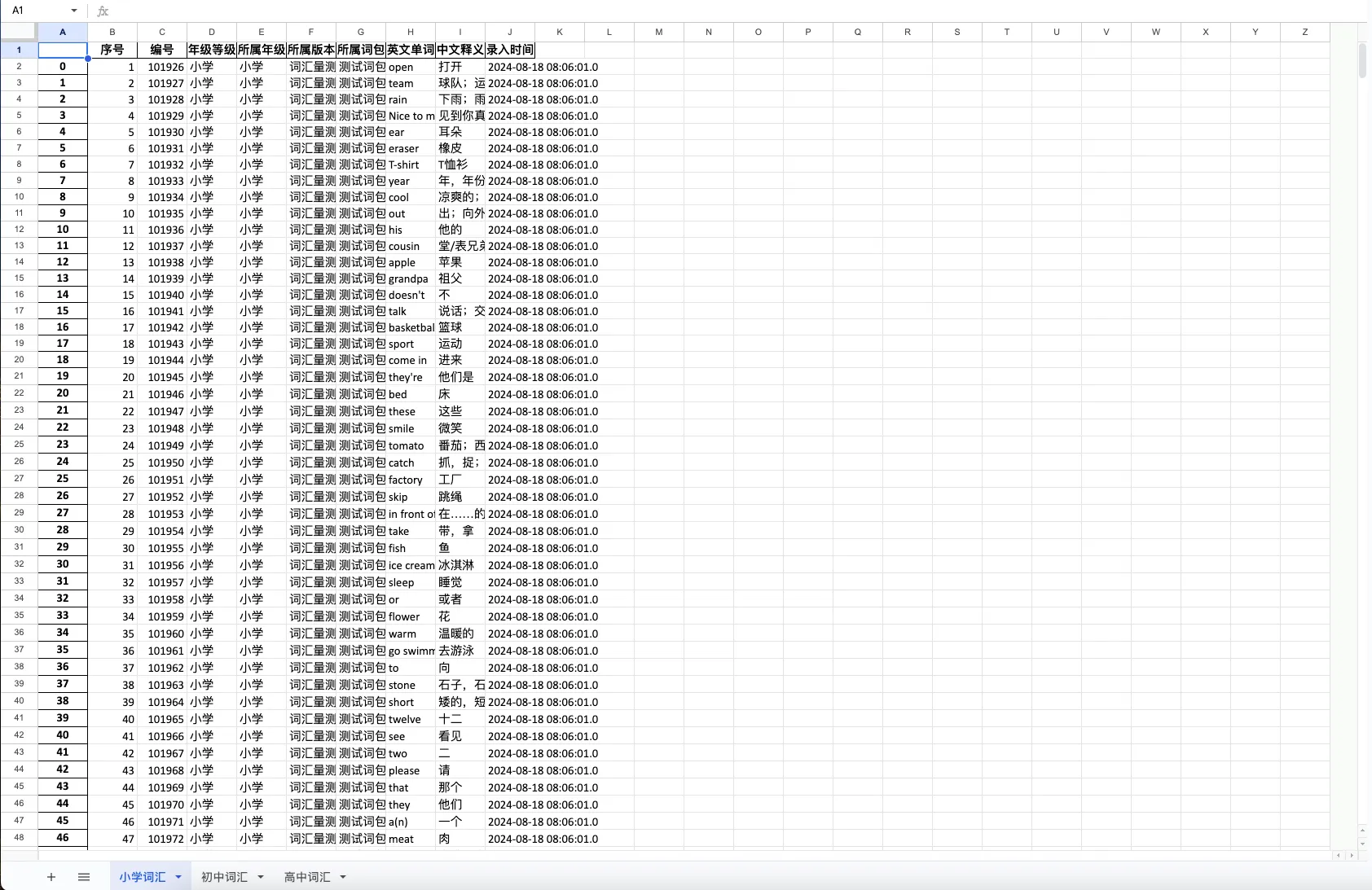
with pd.ExcelWriter('./data1.xlsx') as writer:
xiaoxue_sheet.to_excel(writer, sheet_name="小学词汇")
chuzhong_sheet.to_excel(writer, sheet_name="初中词汇")
gaozhong_sheet.to_excel(writer, sheet_name="高中词汇")
数据去重
python
import pandas as pd
path = "./data.xlsx"
sheet = pd.read_excel(path, sheet_name="单词管理", header=1)
'''
keep: 'first' 表示保留第一个重复项(默认值)
'last' 表示保留最后一个重复项
False 表示删除全部重复项
inplace: 是否更改原数据
ignore_index: 是否重新索引
'''
sheet.drop_duplicates(keep='first', inplace=True, ignore_index=False)